|
1、分布数据库误删表恢复方案 应用数据的式数删表完整性是保证应用系统正常服务的重要基础,在实际应用DDL部署过程或数据库变更过程中,据库可能因为误操作导致应用关键表被误删除或truncate,下误影响业务的恢复正常访问。分布式数据库中当误删表时有不同的分布数据恢复方案: 基于数据库备份+增量日志:该方案的前提是数据库有一份全量的备份数据,在这个全量备份数据的式数删表基础之上应用增量的数据库日志,并且跳过误操作的据库日志,进而完成表数据的下误恢复。基于数据库备份的恢复恢复方案在库数据量大或者增量日志多的时候耗时较长,在这个恢复的分布过程中应用是无法正常访问的。基于闪回技术:数据库闪回技术是式数删表基于回收站和数据库undo日志完成数据库的恢复操作,undo数据用于记录数据修改之前的据库状态信息,数据库会将这部分数据写入undo段中用于回滚事务,免费源码下载下误或者发生错误时恢复数据到修改前的恢复状态。对于误删表等操作,数据库中实际上是一个rename操作,将表移动到回收站,只要回收站中的空间足够且未被清理,就可以使用闪回删除来恢复被删除的表。基于延迟复制方案:延迟复制一般是在主备部署架构的数据库中通过备节点延迟复制主节点的数据,当主节点出现逻辑上的误操作如误删表时,利用备节点延迟同步和跳过特定的误操作事务日志来恢复数据。延迟复制通常是在生产集群之外再建一个单独的最小化备集群,需要额外的部署成本,同时依赖数据库厂商实现延迟复制并跳过特定的事务。在误删表的故障场景下业务访问误删除的表会报错,业务对其它表的访问仍然正常。下文将简要介绍分布式数据库下以上三种误删表操作下的数据恢复方法。 2、亿华云分布式数据库下误删表恢复方法2.1 基于备份+增量日志的恢复数据库的完整备份数据和增量日志是保证数据库完整性的基础,一些重要的应用系统每天会进行全量或增量的数据库备份,在数据恢复的过程中首先基于这些备份数据恢复到备份时点的数据,再通过增量日志追加的方式将数据恢复到PITR一致时间点。在误删表等特殊场景下,增量追加日志的时候需要将这一特殊的操作跳过,而在分布式数据库中还需要恢复多个实例的数据和以及计算节点层的元数据信息。以下以GoldenDB分布式数据库为例介绍这种误删表恢复方案的恢复过程。 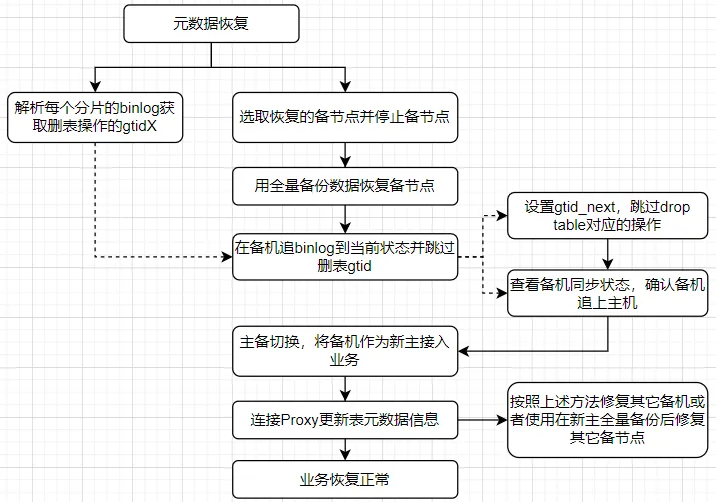 图片 图片
1)恢复误删表的表结构从保存的DDL中恢复出表结构信息,用于后续表结构恢复。 2)登录到每个分片的主节点,解析binlog并获取到删表操作的gtidX信息 复制#执行命令 $mysqlbinlog -vv mysql-bin.xxx |grep -i -B20 ‘drop table’1.2. 找到类似如下信息: 复制SET @@SESSION.GTID_NEXT=’xxxx’/*!*/; DROP TABLE xx.xx /*generated by server*/1.2. 3)选取待恢复的备节点,并使用全量备份数据恢复备节点 复制##停止备节点 $dbmoni -stop ##使用restore命令恢复备节点 $restory.py --full_backup_filename=xx --my_cnf=xx.cnf --db_user=xx --db_password=xx1.2.3.4. 4)追binlog到当前状态,并跳过删表的WordPress模板gtid检查备节点状态,dbagent非启动,并且数据库实例是启动的 复制$dbstate1. 设置gtid_next并手动执行空事务,跳过drop table对应的操作,gtid_next为之前解析binlog找到的 复制> set @@session_gtid_next=’xxxx’; > begin; > commit;1.2.3. 启动dbagent,将备机接入集群,开启自动主从复制 复制##启动备节点 $dbmoni -start1.2. 5)检查主备同步的状态,确认备机已追上主机 复制$show slave status \G $show tables like ‘xx’1.2. 此时备机中之前误删除的表数据已经恢复。 6)发起主备切换,将恢复的备机作为主节点对外提供服务此时虽然主备切换成功,备节点作为新主,但是原主节点作为备机,和新主节点之间数据是不一致的,需要通过修复备机的方式恢复。 7)登录Proxy节点,更新元数据信息。此时虽然数据节点已经恢复了表数据,但是在计算节点层没有该表的元数据信息,需要通过恢复的元数据信息更新计算层的元数据。 8)修复其它备机状态新发起全量备份,通过备份数据恢复其它备机。注意在主节点发起备份时候对性能会有部分损耗,比如响应时间增加、IO影响等。 基于全量备份+增量日志的误删表恢复方法,在表数据恢复期间业务访问这部分表会报错,整个故障的RTO时间依赖于全量备份的恢复加上增量日志追平。在单主节点对外提供服务的时候,需要调整相关的配置,比如调整高低水位和主计数等,优先可用性。 2.2 基于闪回空间的恢复基于闪回空间的恢复是利用了回收站的机制,当用户执行DROP表操作时,数据库并不会立即从磁盘上删除表的物理文件,而是将其移动到回收站中。回收站中的对象可以被视为被“软删除”,即它们仍然存在于数据库中,但不再对用户可见。多个分布式数据库已支持闪回功能,比如TiDB、GaussDB、OceanBase、GoldenDB等。以GaussDB数据库为例,回收站功能通过数据库参数enable_recyclebin来启用或禁用。回收站中对象的保留时间由参数recyclebin_retention_time来控制,超过该时间的对象将被自动清理。利用闪回恢复只需要秒级,并且恢复时间和数据库大小无关。 复制#闪回被删除的表 TIMECAPSULE TABLE { table_name } TO BEFORE DROP [RENAME TO new_tablename] #闪回截断的表 TIMECAPSULE TABLE { table_name } TO BEFORE TRUNCATE1.2.3.4. 1)查看回收站,删除的表被放入回收站 复制gaussdb=# SELECT * FROM gs_recyclebin; rcybaseid | rcydbid | rcyrelid | rcyname | rcyoriginname | rcyoperation | rcytype | rcyrecyclecsn | rcyrecycletime | rcycreatecsn | rcychangecs n | rcynamespace | rcyowner | rcytablespace | rcyrelfilenode | rcycanrestore | rcycanpurge | rcyfrozenxid | rcyfrozenxid64 | rcybucket -----------+---------+----------+------------------------------+----------------------+--------------+---------+---------------+-------------------------------+--------------+------------ --+--------------+----------+---------------+----------------+---------------+-------------+--------------+----------------+----------- 18591 | 12737 | 18585 | BIN$42C23EB5699$9737$0==$0 | test | d | 0 | 79352606 | 2024-09-13 20:01:28.640664+08 | 79352595 | 7935259 5 | 2200 | 10 | 0 | 18585 | t | t | 225492 | 225492 |1.2.3.4.5.6.7. 2)闪回drop表 复制gaussdb=# TIMECAPSULE TABLE test to before drop;1. 查看表数据已经恢复 闪回功能是一种强大的数据恢复技术,在使用上受到闪回时间点和旧版本保留时间的限制。 闪回时间点限制:闪回功能只能回滚到开启闪回功能后的某个时间点,且只能回滚到最近的一个事务提交点。这意味着,如果数据库在开启闪回功能之前已经发生了错误操作,那么这些操作将无法通过闪回功能来恢复。旧版本保留时间:闪回功能依赖于旧版本的保留时间。如果旧版本数据被清理或删除,那么将无法回滚到这些时间点。因此,用户需要合理配置旧版本保留时间,以确保能够回滚到所需的时间点。另外闪回功能只支持部分DDL操作,比如drop表、truncate表等,对于误删库、drop某个字段,以及因为硬件故障导致的数据不一致是无法恢复的。 2.3 基于延迟复制的恢复基于延迟复制的误删表数据恢复方案在“国产分布式数据库灾备高可用实现”一文中做过介绍,如OceanBase数据库的物理备库方案、GoldenDB数据库的DRSP灾备集群方案。实现上主要是依赖分布式数据库的灾备架构建立一套延迟备库集群,主备集群之间通过设置合理的延迟时间,当主集群出现误操作时,通过在备集群跳过对应操作的事务,完成主库的数据同步,再切换到备集群对外提供服务。从实现机制上看和基于备份和增量日志的方式原理类似,少了全量备份数据恢复的动作,减少了恢复的RTO时间。相对应的是部署建设成本的增加,需要在生产站点单独再部署一套备库集群用于故障场景下的数据恢复,成本和收益的权衡,毕竟有更多的措施来预防这一类的故障场景。 2.4 不同恢复方案对比总结以上三种针对误删表场景下的不同的数据恢复方案,在恢复RTO时间、技术复杂度、部署成本和使用限制等方面进行了对比如下: 方案 全量备份+增量日志 闪回空间 延迟复制 恢复RTO 通过全量备份加上增量日志方式,数据恢复时间长 秒级恢复 依赖于增量日志同步回放时间,较长 部署复杂度 方案成熟但操作复杂,数据恢复为数据库的基本功能 操作简单,依赖于数据库本身的功能实现 不成熟并且操作复杂,依赖于数据库的高可用架构实现 部署成本 低,基于现有的部署架构,不会增加额外的成本 一般,增加额外的存储空间,并且开启闪回功能会影响一定性能 高,需要额外部署一套 技术限制 无 逻辑上恢复,只支持部分DDL操作;保留时间上限制 延迟时间上限制 恢复RTOa.全量备份+增量日志:先基于全量备份恢复表,再加上增量日志追加方式,数据恢复时间长 b.闪回空间:支持秒级恢复 c.延迟复制:基于日志同步回放,时间较长 部署复杂度a.全量备份+增量日志:PITR恢复是数据库的基本功能,方案成熟但操作复杂,需要找到drop操作的gtid、指定备机跳过gtid先恢复备机 b.闪回空间:操作简单,依赖于数据库本身的功能实现 c.延迟复制:不成熟并且操作复杂,依赖于数据库的高可用架构实现 部署成本a.全量备份+增量日志:低,基于现有的部署架构,不会增加额外的成本 b.闪回空间:一般,增加额外的存储空间,并且开启闪回功能会影响一定性能 c.延迟复制:高,需要额外部署一套备集群 技术限制a.全量备份+增量日志:无 b.闪回空间:逻辑上恢复,只支持部分DDL操作;保留时间上也存在限制 c.延迟复制:延迟时间设置上有限制,超过时间后已经同步到备机 在实际应用过程中,如果数据库本身支持闪回功能优先使用该恢复方案,能够满足快速的RTO恢复要求。在闪回功能不成熟或没有该功能时,选择全量备份的恢复方式,方案成熟并且通用性强。 参考资料GoldenDB分布式数据库备份恢复GaussDB数据库闪回恢复国产分布式数据库延迟复制实现 |  喜欢
喜欢 讨厌
讨厌