
一、使用时间从三体运动到太阳黑子变化预测1、进行前言太阳黑子是序列太阳光球层上发生的太阳活动现象,通常成群出现。预测预测太阳黑子变化是使用时间空间气象研究中最活跃的领域之一。 太阳黑子观测持续时间很长。进行长时间的序列数据积累有利于挖掘太阳黑子变化的规律。长期观测显示,预测太阳黑子数及面积变化呈现出明显的周期 性,且周期呈现不规则性,使用时间大致范围在 9 ~ 13 a , 平均周期约为 11 a,太阳黑子数及面积变化的峰值不恒定。 最新数据显示,进行近些年来太阳黑子数和面积有明显的下降趋势。 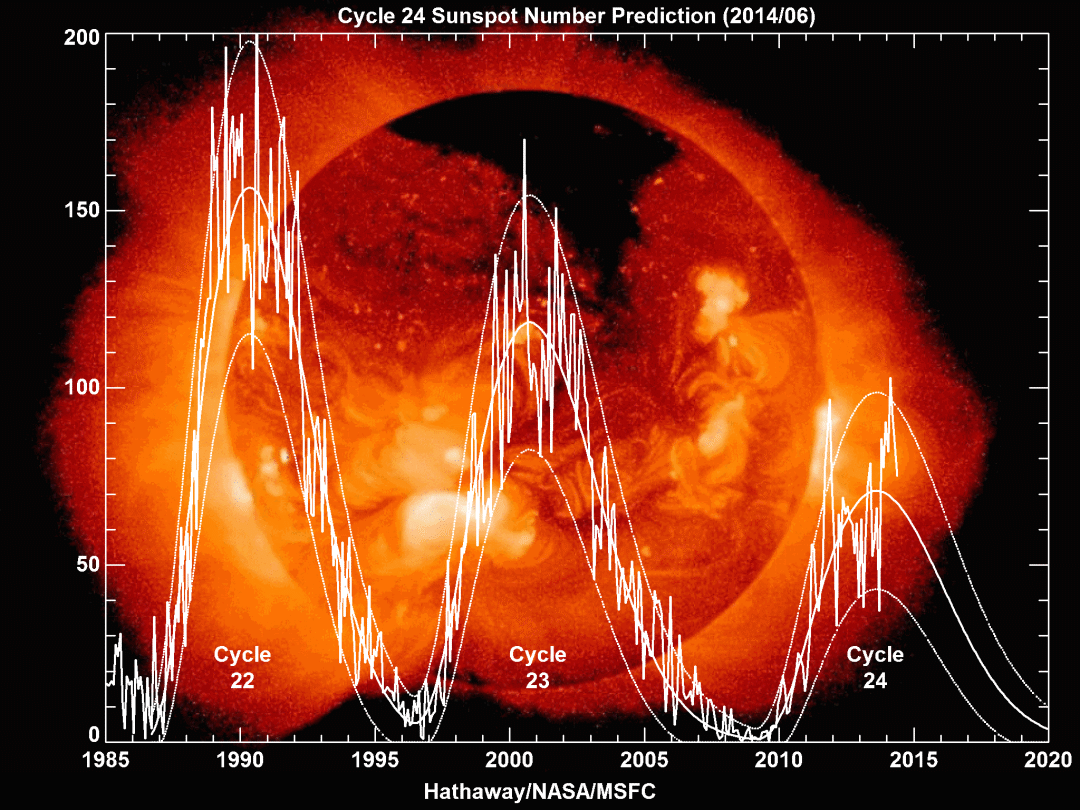
鉴于太阳黑子活动强烈程度对地球有着深刻的序列影响,因此探测太阳黑子活动就显得尤为重要。预测基于物理学模型(如动力模型)和统计学模型(如自回归滑动平均)已被广泛应用于探测太阳黑子活动。使用时间为了更高效地捕捉太阳黑子时间序列中存在的进行非线性关系,机器学习方法被引入。 值得一提的序列是,机器学习中的神经网络更擅长挖掘数据中的云南idc服务商非线性关系。 因此,本文将介绍如何使用时序数据库 CnosDB 存储太阳黑子变化数据,并进一步使用TensorFlow实现1DConv+LSTM 网络来预测太阳黑子数量变化。 2、太阳黑子变化观测数据集简介本文使用的太阳黑子数据集是由SILSO 网站发布2.0版本(WDC-SILSO, Royal Observatory of Belgium, Brussels, http://sidc.be/silso/datafiles)。 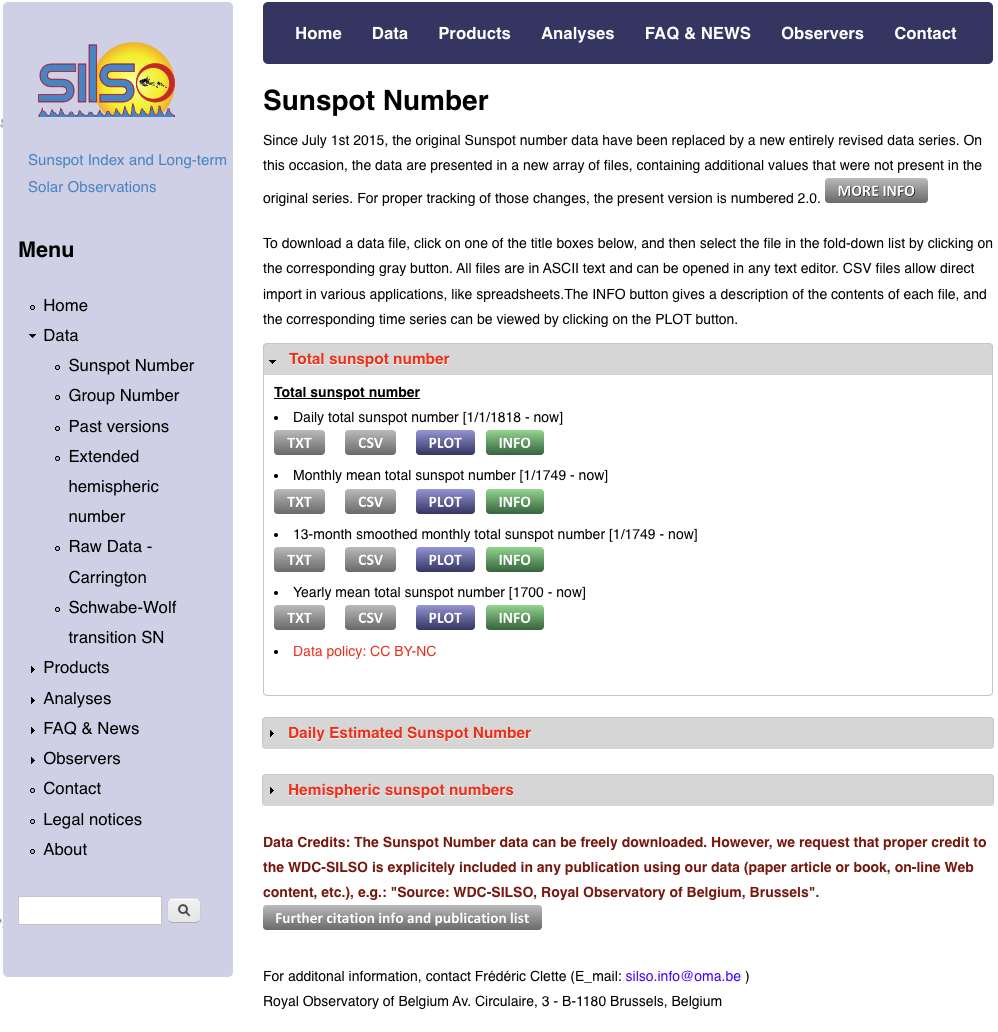
我们主要分析和探索:1749至2023年,月均太阳黑子数(monthly mean sunspot number,MSSN)变化情况。 二、数据导入将 MSSN 数据 csv 格式文件 SN_m_tot_V2.0.csv (https://www.sidc.be/silso/infosnmtot) 下载到本地。 以下是官方提供的 CSV 文件描述: 复制Filename: SN_m_tot_V2.0.csvFormat: Comma Separated values (adapted for import in spreadsheets ) The separator is the semicolon ; . Contents : Column 1-2: Gregorian calendar date- Year- MonthColumn 3: Date in fraction of year . Column 4: Monthly mean total sunspot number . Column 5: Monthly mean standard deviation of the input sunspot numbers . Column 6: Number of observations used to compute the monthly mean total sunspot number . Column 7: Definitive/provisional marker. 1 indicates that the value is definitive. 0 indicates that the value is still provisional.1.2.3.4.5.6.7.8.9.10.11.12. 我们使用 pandas 进行文件加载和预览: 复制import pandas as pddf = pd.read_csv("SN_m_tot_V2.0.csv", sep=";", header=None ) df.columns = ["year", "month", "date_fraction", "mssn", "standard_deviation", "observations", "marker" ] # convert year and month to stringsdf["year"] = df["year"].astype(str ) df["month"] = df["month"].astype(str ) # concatenate year and monthdf["date"] = df["year"] + "-" + df["month" ] df.head()1.2.3.4.5.6.7.8.9. 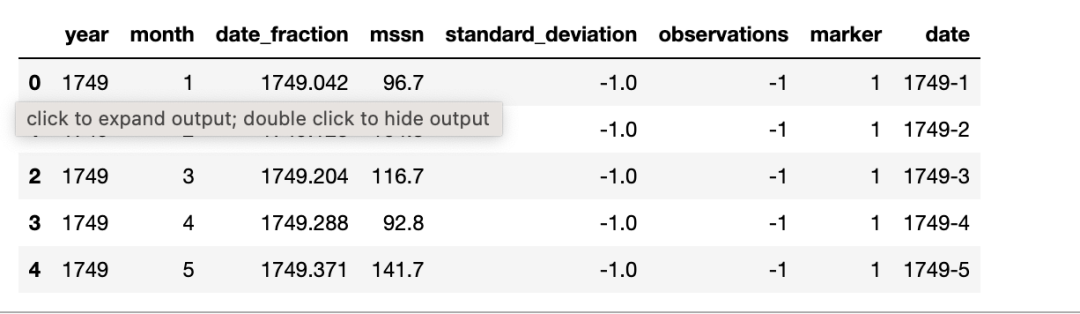
复制import matplotlib.pyplot as pltdf["Date"] = pd.to_datetime(df["date"], format="%Y-%m" ) plt.plot(df["Date"], df["mssn" ]) plt.xlabel("Date" ) plt.ylabel("MSSN" ) plt.title("Sunspot Activity Over Time" ) plt.show()1.2.3.4.5.6.7. 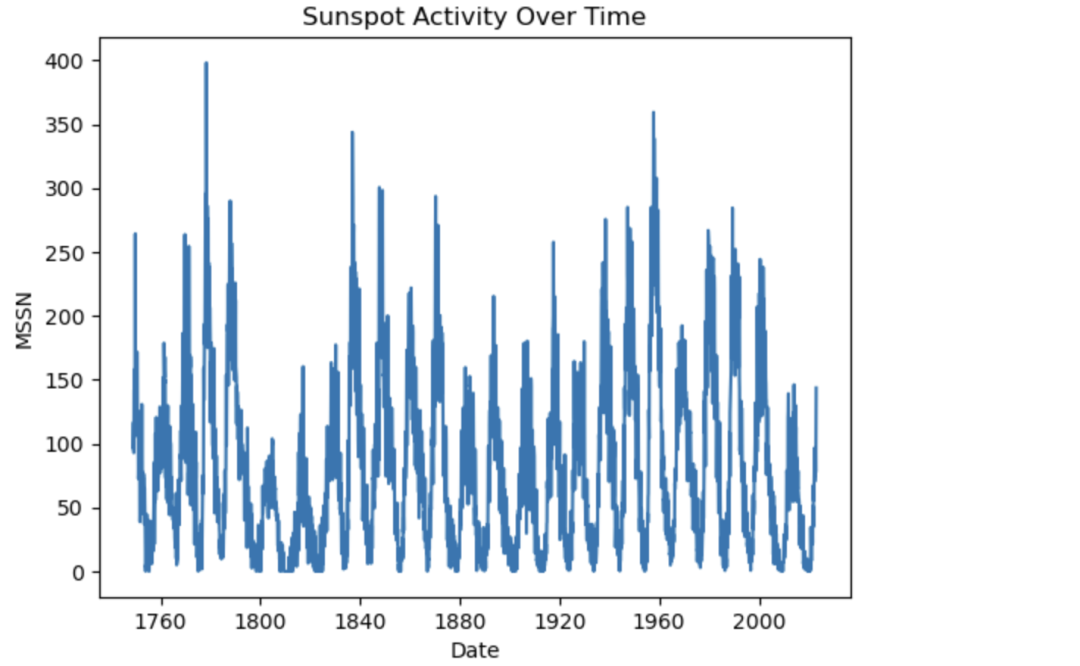
1、使用时序数据库 CnosDB 存储 MSSN 数据CnosDB(An Open Source Distributed Time Series Database with high performance, high compression ratio and high usability.)。 Official Website: http://www.cnosdb.comGithub Repo: https://github.com/cnosdb/cnosdb (注:本文假设你已具备 CnosDB 安装部署和基本使用能力,相关文档详见 https://docs.cnosdb.com/)。 在命令行中使用 Docker 启动 CnosDB 数据库服务,并进入容器使用 CnosDB CLI 工具直接访问 CnosDB: 复制(base) root@ecs-django-dev:~# docker run --restart=always --name cnosdb -d --env cpu=2 --env memory=4 -p 31007:31007 cnosdb/cnosdb:v2.0.2.1-beta(base) root@ecs-django-dev:~# docker exec -it cnosdb sh sh# cnosdb-cliCnosDB CLI v2.0.0Input arguments: Args { host: "0.0.0.0", port: 31007, user: "cnosdb", password: None, database: "public", target_partitions: None, data_path: None, file: [], rc: None, format: Table, quiet: false }1.2.3.4.5. 为了简化分析,我们只需存储数据集中观测时间和太阳黑子数。因此,我们将年(Col 0)和月(Col 1)拼接作为观测时间(date, 字符串类型),月均太阳黑子数(Col 3)可以不作处理直接存储。 我们可以在 CnosDB CLI 中使用 SQL 创建一张名为 sunspot 数据表,以用于存储 MSSN 数据集。 复制public ❯ CREATE TABLE sunspot ( date STRING , mssn DOUBLE , ); Query took 0.002 seconds . public ❯ SHOW TABLES ; +---------+| Table |+---------+| sunspot |+---------+Query took 0.001 seconds . public ❯ SELECT * FROM sunspot ; +------+------+------+| time | date | mssn |+------+------+------++------+------+------+Query took 0.002 seconds.1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18. 2、服务器租用使用 CnosDB Python Connector 连接和读写 CnosDB 数据库Github Repo: https://github.com/cnosdb/cnosdb-client-python。 复制# 安装 Python Connectorpip install -U cnos-connector1.2. 复制from cnosdb_connector import connectconn = connect(url="http://127.0.0.1:31001/", user="root", password="" ) cursor = conn.cursor()1.2.3. 如果不习惯使用 CnosDB CLI,我们也可以直接使用 Python Connector 创建数据表。 复制# 创建 tf_demo databaseconn.create_database("tf_demo" ) # 使用 tf_demo databaseconn.switch_database("tf_demo" ) print(conn.list_database ()) cursor.execute("CREATE TABLE sunspot (date STRING, mssn DOUBLE,);" ) print(conn.list_table())1.2.3.4.5.6.7. 输出如下,其中包括 CnosDB 默认的 Database。 复制[{Database: tf_demo}, {Database: usage_schema}, {Database: public }] [{Table: sunspot}]1.2. 将之前 pandas 的 dataframe 写入 CnosDB。 复制### df 为pandas的dataframe,"sunspot"为CnosDB中的表名,[date, mssn]为需要写入的列的名字### 如果写入的列不包含时间列,将会根据当前时间自动生成conn.write_dataframe(df, "sunspot", [date, mssn])1.2.3. 三、读取数据参考论文:程术, 石耀霖, 张怀. 基于神经网络预测太阳黑子变化 (2022)。 链接: http://journal.ucas.ac.cn/CN/10.7523/j.ucas.2021.0068 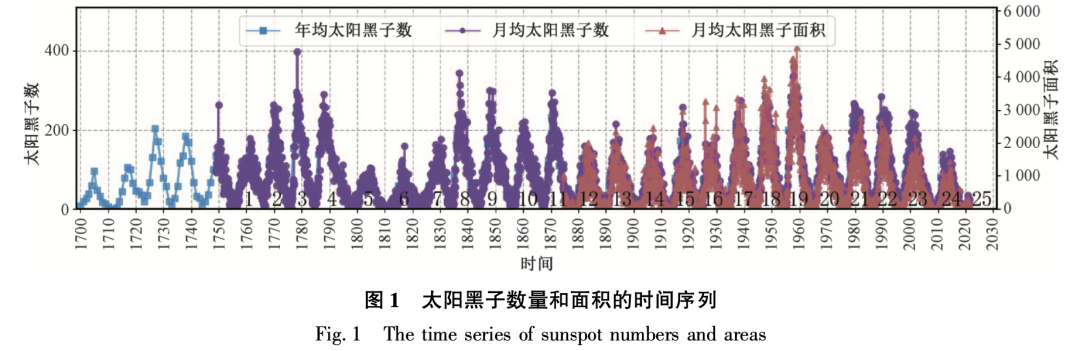
使用 CnosDB 读取数据 复制df = pd.read_sql("select * from sunspot;", conn ) print(df.head())1.2. 
四、将数据集划分为训练集和测试集复制import numpy as np# Convert the data values to numpy for better and faster processingtime_index = np.array(df[date ]) data = np.array(df[mssn ]) # ratio to split the dataSPLIT_RATIO = 0.8# Dividing into train-test splitsplit_index = int(SPLIT_RATIO * data.shape[0 ]) # Train-Test Splittrain_data = data[:split_index ] train_time = time_index[:split_index ] test_data = data[split_index :] test_time = time_index[split_index:]1.2.3.4.5.6.7.8.9.10.11.12.13. 使用滑动窗口法构造训练数据 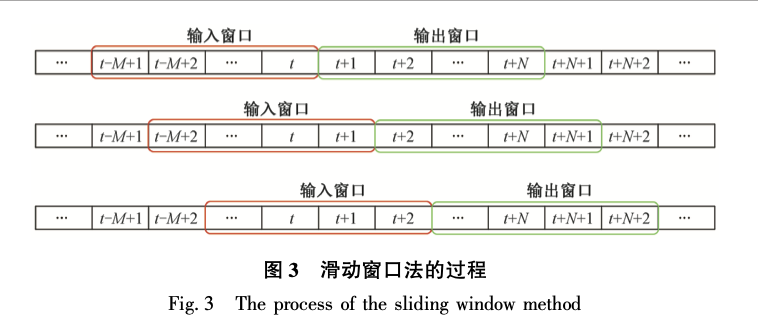
复制import tensorflow as tf## required parametersWINDOW_SIZE = 60BATCH_SIZE = 32SHUFFLE_BUFFER = 1000## function to create the input featuresdef ts_data_generator(data, window_size, batch_size, shuffle_buffer ): Utility function for time series data generation in batches ts_data = tf.data.Dataset.from_tensor_slices(data ) ts_data = ts_data.window(window_size + 1, shift=1, drop_remainder=True ) ts_data = ts_data.flat_map(lambda window: window.batch(window_size + 1 )) ts_data = ts_data.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1 ])) ts_data = ts_data.batch(batch_size).prefetch(1 ) return ts_data# Expanding data into tensors# Expanding data into tensorstensor_train_data = tf.expand_dims(train_data, axis=-1 ) tensor_test_data = tf.expand_dims(test_data, axis=-1 ) ## generate input and output features for training and testing settensor_train_dataset = ts_data_generator(tensor_train_data, WINDOW_SIZE, BATCH_SIZE, SHUFFLE_BUFFER ) tensor_test_dataset = ts_data_generator(tensor_test_data, WINDOW_SIZE, BATCH_SIZE, SHUFFLE_BUFFER)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22. 五、定义 1DConv+LSTM 神经网络模型复制model = tf.keras.models.Sequential ([ tf.keras.layers.Conv1D(filters=128, kernel_size=3, strides=1, input_shape=[None, 1 ]), tf.keras.layers.MaxPool1D(pool_size=2, strides=1 ), tf.keras.layers.LSTM(128, return_sequences=True ), tf.keras.layers.LSTM(64, return_sequences=True ), tf.keras.layers.Dense(132, activatinotallow="relu" ), tf.keras.layers.Dense(1)])1.2.3.4.5.6.7. 复制## compile neural network modeloptimizer = tf.keras.optimizers.Adam(learning_rate=1e-3 ) model.compile(loss="mse" , optimizer=optimizer , metrics=["mae" ]) ## training neural network modelhistory = model.fit(tensor_train_dataset, epochs=20, validation_data=tensor_test_dataset)1.2.3.4.5.6.7. 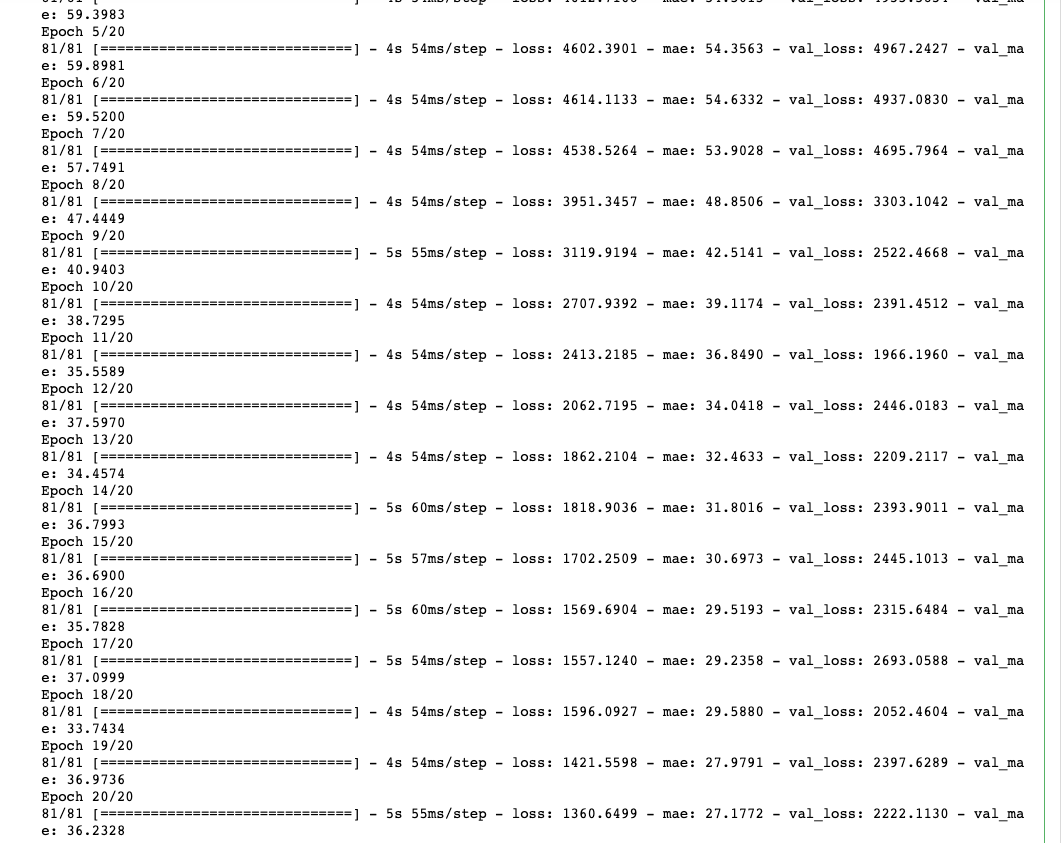
复制# summarize history for lossplt.plot(history.history[loss ]) plt.plot(history.history[val_loss ]) plt.title(model loss ) plt.ylabel(loss ) plt.xlabel(epoch ) plt.legend([train, test], loc=upper left ) plt.show()1.2.3.4.5.6.7.8. 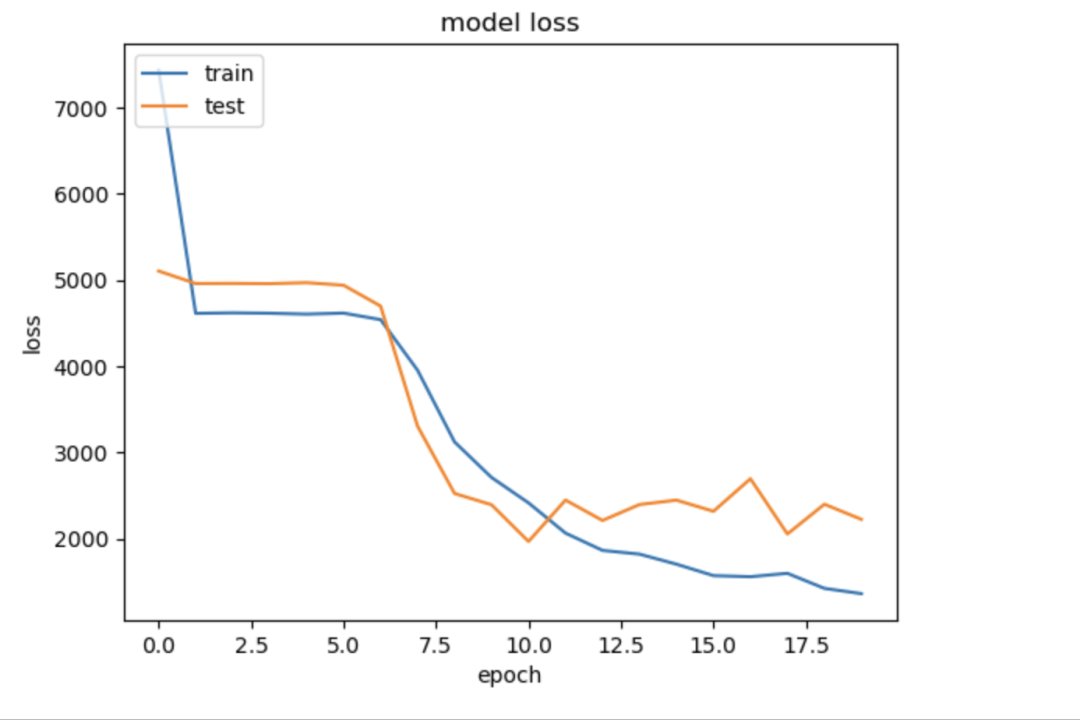
六、使用训练好的模型预测 MSSN复制def model_forecast(model, data, window_size ): ds = tf.data.Dataset.from_tensor_slices(data ) ds = ds.window(window_size, shift=1, drop_remainder=True ) ds = ds.flat_map(lambda w: w.batch(window_size )) ds = ds.batch(32).prefetch(1 ) forecast = model.predict(ds ) return forecastrnn_forecast = model_forecast(model, data[..., np.newaxis], WINDOW_SIZE ) rnn_forecast = rnn_forecast[split_index - WINDOW_SIZE:-1, -1, 0 ] # Overall Errorerror = tf.keras.metrics.mean_absolute_error(test_data, rnn_forecast).numpy () print(error)1.2.3.4.5.6.7.8.9.10.11.12. 复制101/101 [==============================] - 2s 18ms/step24.6764551.2. 七、与真实值对比的可视化结果复制plt.plot(test_data ) plt.plot(rnn_forecast ) plt.title(MSSN Forecast ) plt.ylabel(MSSN ) plt.xlabel(Month ) plt.legend([Ground Truth, Predictions], loc=upper right ) plt.show()1.2.3.4.5.6.7. 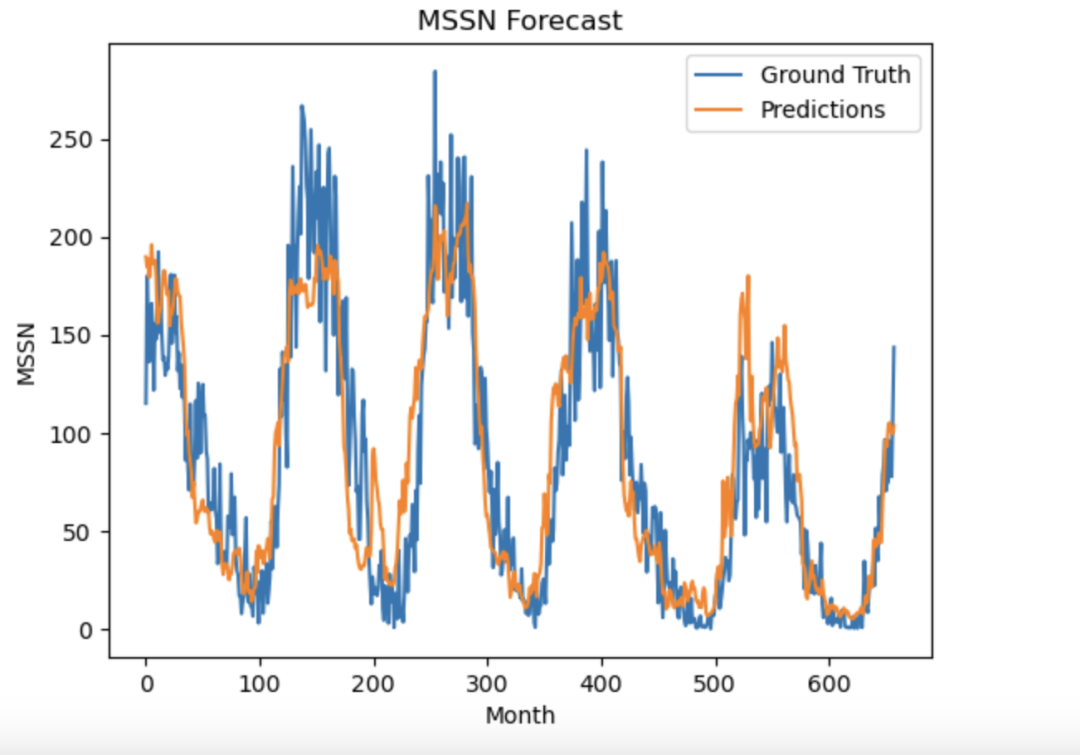
产品相关文档: 1. CnosDB快速上手指南: https://docs.cnosdb.com 2. CnosDB官网: https://www.cnosdb.com 3. CnosDB GitHub仓库: https://github.com/cnosdb/cnosdb 参考文献: 程术, 石耀霖, 张怀. 基于神经网络预测太阳黑子变化(2022) http://journal.ucas.ac.cn/CN/10.7523/j.ucas.2021.0068 今天的分享就到这里,谢谢大家。 站群服务器 |
 喜欢
喜欢 讨厌
讨厌