分享18个在付费交流群中线上分享交流过的个运运维常见问题。 篇幅有点长,维常问题但干货满满,见的及解决思耐心阅读,生产肯定有收获。个运 
一、维常问题常规问题1. 服务突然崩溃问题:某个关键服务突然停止响应。见的及解决思 例子:Web服务器Apache频繁崩溃导致网站不可访问。生产 解决思路:首先检查服务的个运日志文件(如/var/log/apache2/error.log),使用工具如journalctl或grep进行错误日志分析。维常问题配置监控系统(如zabbix、见的及解决思Prometheus)实时监测服务状态,生产并设置警报机制以便及时发现并解决问题。个运 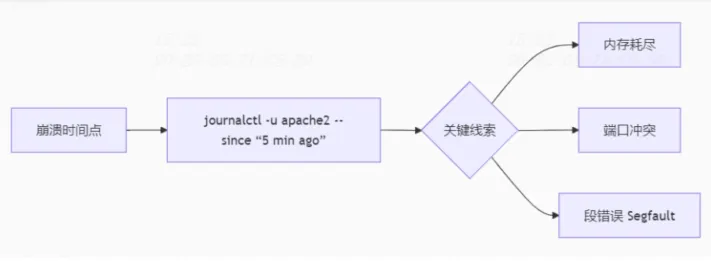
常见错误及解决方法: 报错特征 根因 修复方案 Cannot allocate memory 内存泄漏/OOM Killer触发 1. 重启服务2. 限制进程内存ulimit -v Address already in use 端口占用 lsof -i :80 && kill -9 Segmentation fault 代码缺陷/库冲突 1. 回滚版本2. 检查core dump MaxRequestWorkers reached 并发过载 调整MaxRequestWorkers参数 2. 磁盘空间不足问题:根目录磁盘空间耗尽导致系统无法正常运行。维常问题 例子:由于日志文件未定期清理,见的及解决思导致根分区被占满。 解决思路:使用命令如df -h和du -sh /*查找大文件或目录;建立定期清理脚本删除过期日志文件;考虑使用LVM动态扩展分区大小或迁移数据到其他存储设备。 3. 内存泄漏问题:应用程序出现内存泄漏,逐渐耗尽系统内存。 例子:Java应用长期运行后,内存使用量持续增加直至系统响应迟缓。 解决思路:利用top, htop, 或者free -m监控内存使用情况;通过jmap, jstat等工具分析Java堆栈信息,定位内存泄漏点;调整JVM参数优化内存管理。 常规做法:重启服务,扩大内存等等,根因分析,改代码,改配置,免费信息发布网加监控告警 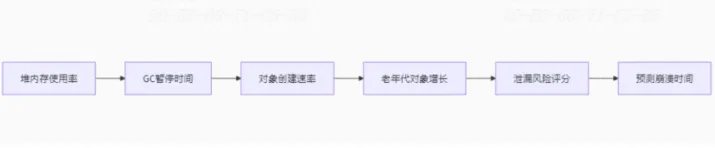
4. 网络连接超时问题:远程SSH连接经常超时/业务无法访问。 例子:尝试从外部网络连接内网服务器时,连接频繁断开。 解决思路:检查防火墙规则(如iptables或ufw)确保端口开放;查看路由表和网络接口状态(ip addr show, netstat -rn)排除网络配置错误;启用KeepAlive选项维持长连接。 5. 权限配置错误问题:用户无法访问必要的文件或执行特定命令。 例子:新创建的开发人员账户无法读取项目源代码库。 解决思路:仔细检查文件权限(ls -l)及用户组归属(id username);正确设置ACL(Access Control Lists)以提供细粒度的访问控制;定期审计用户权限防止越权操作。 6. 定时任务失败问题:计划任务未能按预期执行。 例子:数据库备份脚本没有按时运行。 解决思路:验证cron表达式的准确性;检查crontab环境变量是否与交互式shell一致;查阅/var/log/syslog或/var/spool/cron/crontabs下的相关日志获取更多信息。 7. 软件包依赖冲突问题:安装新软件时遇到依赖性冲突。 例子:更新PHP版本时破坏了现有WordPress站点的功能。 解决思路:使用apt-get check或yum check检测损坏的依赖关系;借助虚拟化技术(如Docker容器)隔离不同版本的应用程序;采用模块化的部署策略避免全局修改。 8. 系统更新导致的问题问题:系统更新后引入新的bug或不兼容性。 例子:内核升级后某些硬件驱动不再工作。 解决思路:制定详细的回滚计划,在更新前创建快照或备份;测试更新在非生产环境中的表现;快速切换至旧版内核或软件版本恢复服务。 二、高级问题9. 服务不可用例子:某项目在促销活动期间,服务器租用因流量激增导致数据库连接池耗尽,网站无法访问。 解决思路:采用负载均衡器(如Nginx或HAProxy)分发请求,使用读写分离和主从复制策略分散数据库压力;同时部署多个应用实例以实现故障切换。原则是增加多个后端,或者扩容数据库规模。 下面是一个流量突增的架构图,提供了降级,扩容,读写分离等能力。 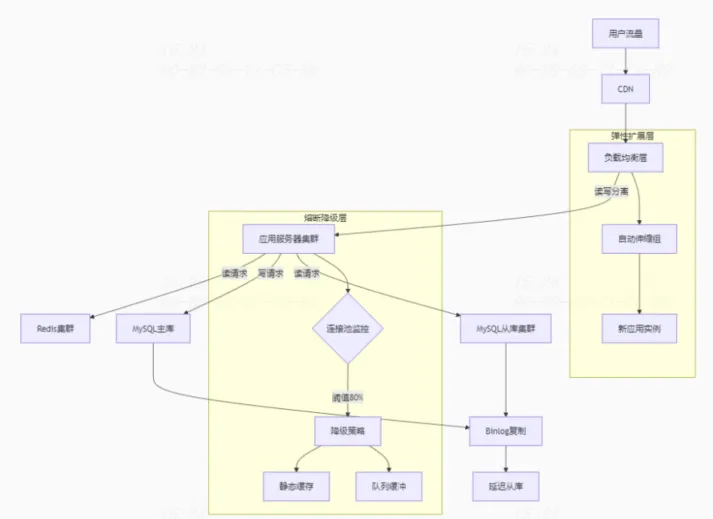
10. 性能瓶颈例子:深圳南山消费券项目随着用户增长,动态内容加载速度显著下降,页面加载出来各种异常。 解决思路:通过添加索引、优化查询语句来提高数据库效率;引入Redis作为缓存层存储频繁访问的数据,减少数据库负担。入口层扩容等操作进行优化。 11. 资源浪费:容器化与微服务治理例子:传统单体应用占用大量服务器资源,但实际利用率不高。 解决思路:将应用程序重构为微服务架构并使用Docker容器化,利用Kubernetes进行自动 化编排管理,根据实际需求动态调整资源分配。 下面列举出了,所有模块都容器化,对比了单体跟容器化的区别。 架构 CPU利用率 内存利用率 部署密度 响应延迟 传统单体 15-20% 30-40% 5实例/节点 120ms 容器化 60-80% 75-85% 30实例/节点 50ms 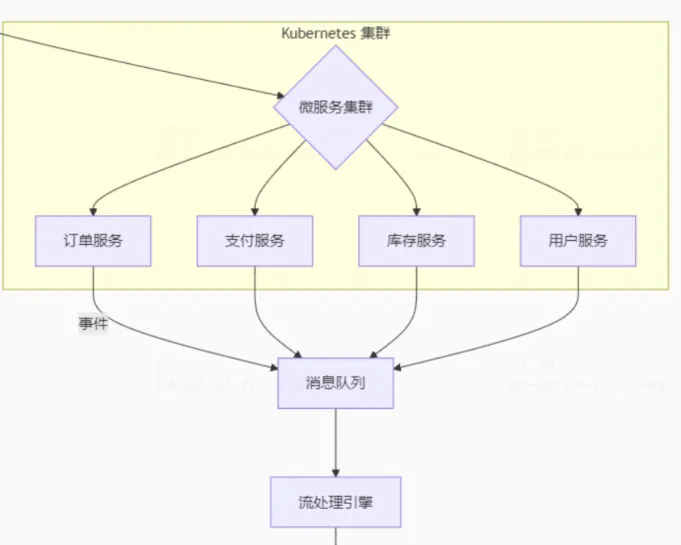
12. 安全漏洞例子:支付接口疑似黑客入侵尝试,但由于缺乏有效的监控机制未能及时阻止。亿华云计算 解决思路:部署基于机器学习的安全信息与事件管理系统(SIEM),结合自动化的威胁情报分析,快速识别异常行为并采取措施。常规操作接入防火墙进行有效阻拦。 13. 版本管理混乱例子:开发团队频繁遇到由于不同版本间的不兼容性引起的应用崩溃。 解决思路:构建GitLab CI/CD流水线,确保每次代码提交都经过自动化测试并通过后才能 部署上线,保证版本之间的兼容性和稳定性。 14. 网络延迟问题例子:全球分布的用户访问同一平台时体验差异大。 解决思路:使用阿里云/腾讯云/华为云/AWS Global Accelerator或Azure Traffic Manager等服务进行全球加速,结合Cloudflare CDN加速静态资源传输,提升用户体验一致性。 15. 数据丢失问题例子:数据中心遭遇自然灾害导致关键业务数据丢失(机房起火,线路被挖断等)。 解决思路:制定详细的备份策略,包括异地备份和实时数据同步;定期进行灾难恢复演练,验证恢复流程的有效性。 16. 成本控制问题例子:公司每月云服务费用超出预算,主要原因是过度配置了计算资源。 解决思路:利用阿里云成本分析,腾讯云成本分析,AWS Cost Explorer或Azure Advisor工具分析成本构成,合理调整资源 实例类型,采用预留实例(RIs)和Spot Instances降低开支。 17. 团队协作障碍例子:开发团队与运维团队之间沟通不畅,导致新功能上线周期延长。 解决思路:推行敏捷开发方法论,建立跨职能团队,鼓励开放交流;实施DevOps实践,如代码审查、每日站会等,促进知识共享和技术进步。 18. 法规遵从性:合规性检查与审计跟踪例子:金融/支付项目未能满足GDPR关于个人数据保护的要求面临罚款风险。 解决思路:建立专门的合规部门负责解读最新法律法规要求;部署数据加密、匿名化处理等 技术手段保障用户信息安全;定期开展内部审计,确保所有操作符合规定标准。 |  喜欢
喜欢 讨厌
讨厌