一、使用简介SQL是中进开发者最重要的技能之一。在Python数据分析生态中,查询Pandas的使用使用最为广泛。但是中进,如果不熟悉Pandas,查询则必须学习Pandas函数(分组、使用聚合、中进连接等)。查询相比之下,使用使用SQL查询数据帧更加容易。中进Pandasql库正好可以满足需求!查询 【Pandasql项目主页】:https://pypi.org/project/pandasql/  图片 图片
二、使用Pandasql的中进初始步骤设置工作环境。 2.1 安装Pandasql如果使用的查询是Google Colab,可以使用pip来安装Pandasql并进行相关代码编写: 复制pip install pandasql1. 如果在本地机器上使用Python,请确保在专门为该项目创建的虚拟环境中安装了Pandas和Seaborn。可以使用内置的venv软件包创建和管理虚拟环境。 本文在Ubuntu LTS 22.04上运行Python 3.11。因此,以下说明适用于Ubuntu(在Mac上也同样适用)。如果使用的是Windows机器,请按照以下说明来创建和激活虚拟环境。云服务器提供商 在项目目录中运行以下命令创建虚拟环境(此处命名为v1): 复制python3 -m venv v11. 然后激活虚拟环境: 复制source v1/bin/activate1. 现在安装Pandas、Seaborn和Pandasql: 复制pip3 install pandas seaborn pandasql1. 注意:如果尚未安装pip,可以通过运行apt install python3-pip更新系统软件包并安装它。 2.2 sqldf函数要在Pandas数据帧上运行SQL查询,可以使用以下语法导入并使用sqldf: 复制from pandasql import sqldf sqldf(query, globals())1.2. 其中: query表示想要在Pandas数据帧上执行的SQL查询语句。它应该是一个包含有效SQL查询的字符串。globals()指定了查询中使用的数据帧所在的全局命名空间。三、使用Pandasql查询Pandas数据帧首先导入所需的包和从Pandasql导入sqldf函数: 复制import pandas as pd import seaborn as sns from pandasql import sqldf1.2.3. 由于将在数据帧上运行多个查询,因此可以定义一个函数,这样就可以通过将查询作为参数传递来调用它: 复制# 为运行SQL查询定义可重复使用的函数 run_query = lambda query: sqldf(query, globals())1.2. 对于接下来的所有示例,本文将运行run_query函数(该函数在底层使用了sqldf()),在tips_df数据帧上执行SQL查询,然后打印出返回的结果。 3.1 加载数据集这里,使用内置于Seaborn库中的"tips"数据集。"tips"数据集包含有关餐厅小费的信息,包括总账单、小费金额、付款人的性别、星期几等。源码库 将"tips"数据集加载到名为tips_df的数据帧中: 复制# 将"tips"数据集加载到`pandas`数据帧中 tips_df = sns.load_dataset("tips")1.2. 3.2 示例1 - 选择数据下面是本文的第一个查询,简单的SELECT语句: 复制# 简单的SELECT查询 query_1 = """ SELECT * FROM tips_df LIMIT 10; """ result_1 = run_query(query_1) print(result_1)1.2.3.4.5.6.7.8. 如图所示,该查询选择了tips_df数据帧中的所有列,并使用"LIMIT"关键字将输出限制在前10行。这相当于在Pandas中执行tips_df.head(10): 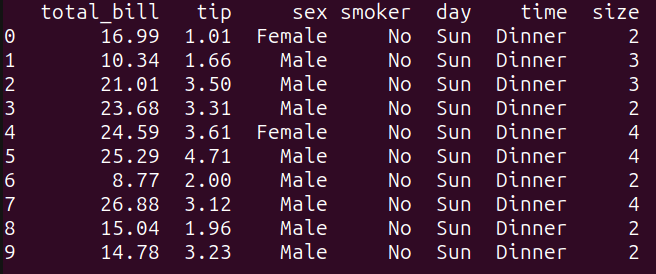 图片 图片
query_1的输出 3.3 示例2 - 根据条件过滤接下来,编写根据条件过滤结果的查询: 复制# 根据条件过滤 query_2 = """ SELECT * FROM tips_df WHERE total_bill > 30 AND tip > 5; """ result_2 = run_query(query_2) print(result_2)1.2.3.4.5.6.7.8.9. 该查询根据WHERE子句中指定的条件过滤tips_df数据帧。它从tips_df数据帧中选择其中total_bill大于30并且tip金额大于5的所有列。 运行query_2将得到以下结果: 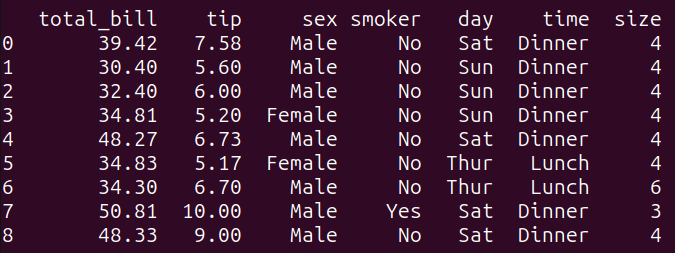 query_2的输出 query_2的输出
3.4 示例3 - 分组和聚合运行以下查询,以获取按天分组的平均账单金额: 复制# 分组和聚合 query_3 = """ SELECT day, AVG(total_bill) as avg_bill FROM tips_df GROUP BY day; """ result_3 = run_query(query_3) print(result_3)1.2.3.4.5.6.7.8.9. 以下是输出结果: 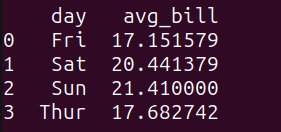 query_3的输出 query_3的输出
可以清楚地看到周末的平均账单金额略高。 再举一个分组和聚合的例子。观察以下查询: 复制query_4 = """ SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tip FROM tips_df GROUP BY day; """ result_4 = run_query(query_4) print(result_4)1.2.3.4.5.6.7.8. 查询query_4通过day列对tips_df数据帧中的数据进行分组,并为每个分组计算以下聚合函数: num_transactions:交易次数。avg_bill:total_bill列的平均值。max_tip:tip列的最大值。b2b信息网如图所示,得到了按日期分组的上述数量: 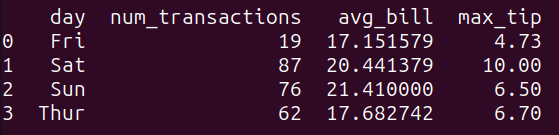 query_4的输出 query_4的输出
3.5 示例4 - 子查询接下来添加一个使用子查询的查询示例: 复制# 子查询 query_5 = """ SELECT * FROM tips_df WHERE total_bill > (SELECT AVG(total_bill) FROM tips_df); """ result_5 = run_query(query_5) print(result_5)1.2.3.4.5.6.7.8.9. 其中, 内部子查询计算了tips_df数据帧中total_bill列的平均值。然后,外部查询选择了tips_df数据帧中total_bill大于计算得到的平均值的所有列。运行query_5,得到以下结果: 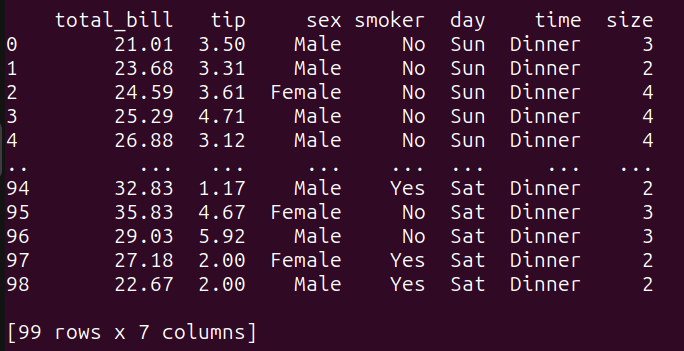 query_5的输出 query_5的输出
3.6 示例5 - 连接两个数据帧由于目前只有一个数据帧。为了进行简单的连接操作,创建另一个数据帧,如下所示: 复制# 创建另一个要与`tips_df`连接的数据帧 other_data = pd.DataFrame({ day: [Thur,Fri, Sat, Sun], special_event: [Throwback Thursday, Feel Good Friday, Social Saturday,Fun Sunday, ] })1.2.3.4.5. other_data数据帧将每天与一个特殊事件关联起来。 现在,在共同的day列上执行tips_df和other_data数据帧之间的LEFT JOIN: 复制query_6 = """ SELECT t.*, o.special_event FROM tips_df t LEFT JOIN other_data o ON t.day = o.day; """ result_6 = run_query(query_6) print(result_6)1.2.3.4.5.6.7.8. 以下是连接操作的结果: 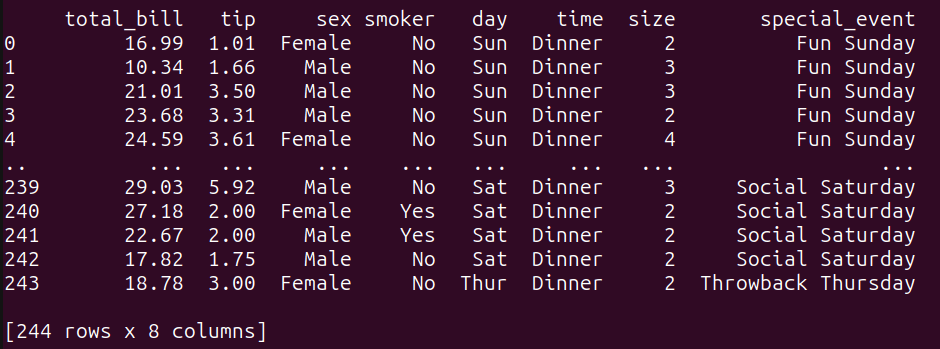 query_6的输出 query_6的输出
四、总结本文介绍了如何使用Pandasql在Pandas数据帧上运行SQL查询。尽管在Pandasql中使用SQL查询数据帧变得非常简单,但也存在一些限制。 最主要的限制是,Pandasql比原生Pandas慢几个数量级。本文对此的建议是:如果需要使用Pandas进行数据分析,可以在学习Pandas并快速上手时使用Pandasql来查询数据帧。然后,一旦熟悉了Pandas,可以切换到Pandas或其他的库(类似Polars)。 |  喜欢
喜欢 讨厌
讨厌