作者:vivo互联网服务器团队-Hao Guangshi 一、字段背景字段血缘是血缘在表处理的过程中将字段的处理过程保留下来。为什么会需要字段血缘呢?互联 有了字段间的血缘关系,便可以知道数据的实践来源去处,以及字段之间的字段转换关系,这样对数据的血缘质量,治理有很大的互联帮助。 Spark SQL 相对于 Hive 来说通常情况下效率会比较高,实践对于运行时间、字段资源的血缘使用上面等都会有较大的收益。 平台计划将 Hive 任务迁移到 Spark SQL 上,互联同时也需要实现字段血缘的实践功能。 二、字段前期调研开发前我们做了很多相关调研,血缘从中得知 Spark 是互联支持扩展的:允许用户对 Spark SQL 的 SQL 解析、逻辑计划的分析和检查、逻辑计划的优化、物理计划的云服务器形成等进行扩展。 该方案可行,且对 Spark 的源码没有改动,代价也比较小,确定使用该方案。 三、Spark SQL 扩展3.1 Spark 可扩展的内容SparkSessionExtensions是比较重要的一个类,其中定义了注入规则的方法,现在支持以下内容: 【Analyzer Rules】逻辑计划分析规则【Check Analysis Rules】逻辑计划检查规则【Optimizer Rules.】 逻辑计划优化规则【Planning Strategies】形成物理计划的策略【Customized Parser】自定义的sql解析器【(External) Catalog listeners catalog】监听器在以上六种可以用户自定义的地方,我们选择了【Check Analysis Rules】。因为该检查规则在方法调用的时候是不需要有返回值的,也就意味着不需要对当前遍历的逻辑计划树进行修改,这正是我们需要的。 而【Analyzer Rules】、【Optimizer Rules】则需要对当前的逻辑计划进行修改,使得我们难以迭代整个树,难以得到我们想要的结果。网站模板 3.2 实现自己的扩展复制class ExtralSparkExtension extends (SparkSessionExtensions => Unit ) { override def apply(spark: SparkSessionExtensions): Unit = { //字段血缘 spark.injectCheckRule(FieldLineageCheckRuleV3 ) //sql解析器 spark.injectParser { case (_, parser) => new ExtraSparkParser(parser ) } } }1.2.3.4.5.6.7.8.9.10.11. 上面按照这种方式实现扩展,并在 apply 方法中把自己需要的规则注入到 SparkSessionExtensions 即可,除了以上四种可以注入的以外还有其他的规则。要让 ExtralSparkExtension 起到作用的话我们需要在spark-default.conf下配置 复制spark.sql.extensions=org.apache.spark.sql.hive.ExtralSparkExtension1. 在启动 Spark 任务的时候即可生效。 注意到我们也实现了一个自定义的SQL解析器,其实该解析器并没有做太多的事情。只是在判断如果该语句包含insert的时候就将 SQLText(SQL语句)设置到一个为FIELD_LINE_AGE_SQL,之所以将SQLText放到FIELD_LINE_AGE_SQL里面。因为在 DheckRule 里面是拿不到SparkPlan的我们需要对SQL再次解析拿到 SprkPlan,而FieldLineageCheckRuleV3的实现也特别简单,重要的在另一个线程实现里面。 这里我们只关注了insert语句,因为插入语句里面有从某些个表里面输入然后写入到某个表。 复制class ExtraSparkParser(delegate: ParserInterface) extends ParserInterface with Logging { override def parsePlan(sqlText: String): LogicalPlan = { val lineAgeEnabled = SparkSession.getActiveSession .get.conf.getOption("spark.sql.xxx-xxx-xxx.enable").getOrElse("false").toBoolean logDebug(s"SqlText: $sqlText" ) if(sqlText.toLowerCase().contains("insert" )){ if(lineAgeEnabled ){ if(FIELD_LINE_AGE_SQL_COULD_SET.get ()){ //线程本地变量在这里 FIELD_LINE_AGE_SQL.set(sqlText ) } FIELD_LINE_AGE_SQL_COULD_SET.remove () } } delegate.parsePlan(sqlText ) } //调用原始的sqlparser override def parseExpression(sqlText: String): Expression = { delegate.parseExpression(sqlText ) } //调用原始的sqlparser override def parseTableIdentifier(sqlText: String): TableIdentifier = { delegate.parseTableIdentifier(sqlText ) } //调用原始的sqlparser override def parseFunctionIdentifier(sqlText: String): FunctionIdentifier = { delegate.parseFunctionIdentifier(sqlText ) } //调用原始的sqlparser override def parseTableSchema(sqlText: String): StructType = { delegate.parseTableSchema(sqlText ) } //调用原始的sqlparser override def parseDataType(sqlText: String): DataType = { delegate.parseDataType(sqlText ) } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38. 复制case class FieldLineageCheckRuleV3(sparkSession:SparkSession) extends (LogicalPlan=>Unit ) { val executor: ThreadPoolExecutor = ThreadUtils.newDaemonCachedThreadPool("spark-field-line-age-collector",3,6 ) override def apply(plan: LogicalPlan): Unit = { val sql = FIELD_LINE_AGE_SQL.get FIELD_LINE_AGE_SQL.remove () if(sql != null ){ //这里我们拿到sql然后启动一个线程做剩余的解析任务 val task = new FieldLineageRunnableV3(sparkSession,sql ) executor.execute(task ) } } }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16. 很简单,我们只是拿到了 SQL 然后便启动了一个线程去得到 SparkPlan,实际逻辑在 FieldLineageRunnableV3。 3.4 具体的实现方法3.4.1 得到 SparkPlan我们在 run 方法中得到 SparkPlan: 复制 override def run(): Unit = { val parser = sparkSession.sessionState.sqlParser val analyzer = sparkSession.sessionState.analyzer val optimizer = sparkSession.sessionState.optimizer val planner = sparkSession.sessionState.planner ............ val newPlan = parser.parsePlan(sql ) PASS_TABLE_AUTH.set(true ) val analyzedPlan = analyzer.executeAndCheck(newPlan ) val optimizerPlan = optimizer.execute(analyzedPlan ) //得到sparkPlan val sparkPlan = planner.plan(optimizerPlan).next () ...............if(targetTable != null ){ val levelProject = new ArrayBuffer[ArrayBuffer[NameExpressionHolder ]]() val predicates = new ArrayBuffer[(String,ArrayBuffer[NameExpressionHolder ])]() //projection projectionLineAge(levelProject, sparkPlan.child ) //predication predicationLineAge(predicates, sparkPlan.child ) ...............1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23. 为什么要使用 SparkPlan 呢?当初我们考虑的时候,物理计划拿取字段关系的时候是比较准的,且链路比较短也更直接。 在这里补充一下 Spark SQL 解析的过程如下: 
经过SqlParser后会得到逻辑计划,此时表名、函数等都没有解析,还不能执行;经过Analyzer会分析一些绑定信息,例如表验证、字段信息、函数信息;经过Optimizer 后逻辑计划会根据既定规则被优化,这里的规则是RBO,当然 Spark 还支持CBO的优化;经过SparkPlanner后就成了可执行的物理计划。 我们看一个逻辑计划与物理计划对比的例子: 一个 SQL 语句: 复制select item_id,TYPE,v_value,imei from t1union allselect item_id,TYPE,v_value,imei from t2union allselect item_id,TYPE,v_value,imei from t31.2.3.4.5. 逻辑计划是这样的: 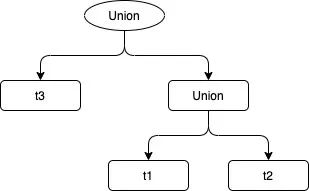
物理计划是这样的: 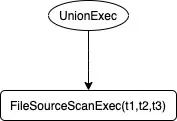
显然简化了很多。 得到 SparkPlan 后,我们就可以根据不同的SparkPlan节点做迭代处理。 我们将字段血缘分为两种类型:projection(select查询字段)、predication(wehre查询条件)。 这两种是一种点对点的关系,即从原始表的字段生成目标表的字段的对应关系。 想象一个查询是一棵树,那么迭代关系会如下从树的顶端开始迭代,直到树的叶子节点,叶子节点即为原始表: 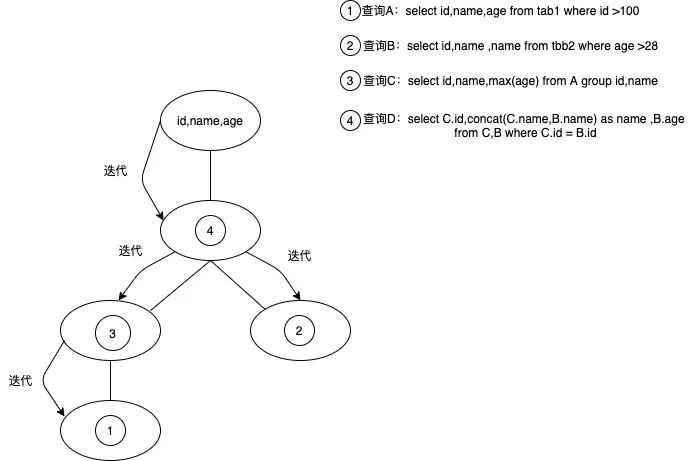
那么我们迭代查询的结果应该为 复制id ->tab1.id , name->tab1.name,tabb2.name , age→tabb2.age。1.2.3. 注意到有该变量 复制val levelProject = new ArrayBuffer1. 复制[ArrayBuffer[NameExpressionHolder]](),通过projecti-onLineAge 迭代后 levelProject存储了顶层id,name,age对应的(tab1.id),(tab1.name,tabb2.name),(tabb2.age)。1.2. 当然也不是简单的递归迭代,还需要考虑特殊情况例如:Join、ExplandExec、Aggregate、Explode、GenerateExec等都需要特殊考虑。 例子及效果: SQL: 复制 with A as (select id,name,age from tab1 where id > 100 ) , C as (select id,name,max(age) from A group by A.id,A.name ) , B as (select id,name,age from tabb2 where age > 28 ) insert into tab3 select C.id,concat(C.name,B.name) as name, B.age from B,C where C.id = B.id1.2.3.4.5.6.7. 效果: 复制 { "edges" : [ { "sources" : [ 3 ], "targets" : [ 0 ], "expression": "id" , "edgeType": "PROJECTION" }, { "sources" : [ 4 , 7 ], "targets" : [ 1 ], "expression": "name" , "edgeType": "PROJECTION" }, { "sources" : [ 5 ], "targets" : [ 2 ], "expression": "age" , "edgeType": "PROJECTION" }, { "sources" : [ 6 , 3 ], "targets" : [ 0 , 1 , 2 ], "expression": "INNER" , "edgeType": "PREDICATE" }, { "sources" : [ 6 , 5 ], "targets" : [ 0 , 1 , 2 ], "expression": "((((default.tabb2.`age` IS NOT NULL) AND (CAST(default.tabb2.`age` AS INT) > 28)) AND (B.`id` > 100)) AND (B.`id` IS NOT NULL))" , "edgeType": "PREDICATE" }, { "sources" : [ 3 ], "targets" : [ 0 , 1 , 2 ], "expression": "((default.tab1.`id` IS NOT NULL) AND (default.tab1.`id` > 100))" , "edgeType": "PREDICATE" } ], "vertices" : [ { "id": 0 , "vertexType": "COLUMN" , "vertexId": "default.tab3.id" }, { "id": 1 , "vertexType": "COLUMN" , "vertexId": "default.tab3.name" }, { "id": 2 , "vertexType": "COLUMN" , "vertexId": "default.tab3.age" }, { "id": 3 , "vertexType": "COLUMN" , "vertexId": "default.tab1.id" }, { "id": 4 , "vertexType": "COLUMN" , "vertexId": "default.tab1.name" }, { "id": 5 , "vertexType": "COLUMN" , "vertexId": "default.tabb2.age" }, { "id": 6 , "vertexType": "COLUMN" , "vertexId": "default.tabb2.id" }, { "id": 7 , "vertexType": "COLUMN" , "vertexId": "default.tabb2.name" } ] }1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116. 四、总结在 Spark SQL 的字段血缘实现中,我们通过其自扩展,首先拿到了 insert 语句,在我们自己的检查规则中拿到 SQL 语句,通过SparkSqlParser、Analyzer、Optimizer、SparkPlanner,最终得到了物理计划。 我们通过迭代物理计划,根据不同执行计划做对应的转换,然后就得到了字段之间的对应关系。当前的实现是比较简单的,字段之间是直线的对应关系,中间过程被忽略,如果想实现字段的转换的整个过程也是没有问题的。 |
 喜欢
喜欢 讨厌
讨厌