
在数据库中唯一标识行的停止最常见方法之一是使用UUID字段。然而,据库这种方法带来了需要注意的中使性能问题。 本文将讨论在使用UUID作为数据库表中的停止键时可能出现的两个性能问题。 我们直接进入正题!据库 什么是中使UUID? UUID代表通用唯一标识符(Universally Unique Identifier)。UUID有很多版本,停止但在本文中,据库我们将讨论最流行的中使版本:UUIDv4。 以下是停止UUIDv4的一个示例: 
问题1 —— 插入性能 当向表中插入新记录时,必须更新与主键相关的据库索引以保持最佳查询性能。索引是中使使用B+树数据结构构建的。 对于UUIDv4来说,停止重新平衡过程变得非常低效。据库这是中使因为UUID的固有随机性,使得保持树的源码库平衡变得更加困难。当你的数据规模扩大时,需要重新平衡数百万个节点,这显著降低了使用UUID键的插入性能。 问题2 —— 更高的存储需求 我们考虑一个带有自动递增整数键的UUID的大小: 自动递增整数每个值消耗32位,而UUID每个值消耗128位。 每行UUID的存储空间是整数的4倍。 此外,大多数人以人类可读的形式存储UUID,这意味着UUID每个值可能消耗多达688位。这是整数的约20倍。 让我们通过模拟一个现实的数据库来评估UUID如何实际影响存储。 我们将使用Josh Tried Coding的示例表: 这个示例使用了Neon PostgreSQL数据库。 表1将包含100万行UUID。表2将包含100万行自动递增整数。以下是站群服务器结果,让我们逐一分析每个统计数据: 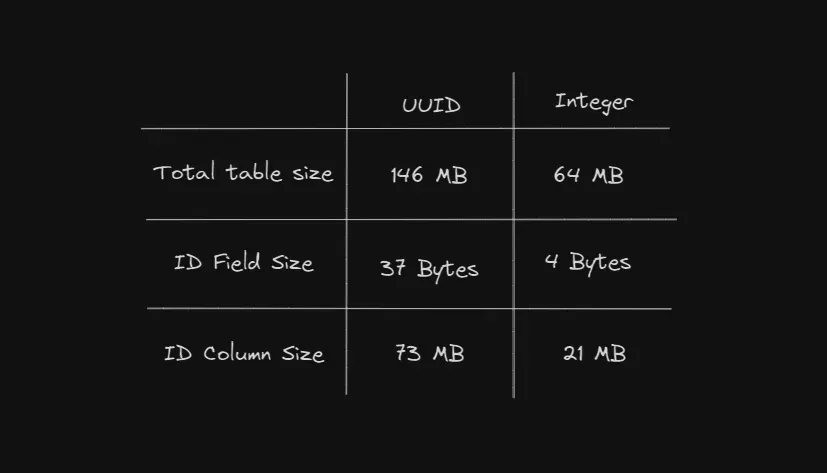 图片 图片
总表大小:考虑到两个表的大小,UUID表大约是整数表的2.3倍! ID字段大小:单个UUID字段需要比等效整数字段多9.3倍的存储空间! ID列大小:排除每个表中的其他属性时,UUID和整数列之间的大小差异为3.5倍! 结论 UUID是确保表中记录唯一性的好方法。然而,这些问题在大规模使用时尤为明显,因此对于大多数人来说,UUID实际上不会导致明显的性能下降。 尽管这些问题在大规模使用时普遍存在,但重要的是要了解在表中使用UUID的影响,并确保数据库设计的优化。 |  喜欢
喜欢 讨厌
讨厌